Abstract
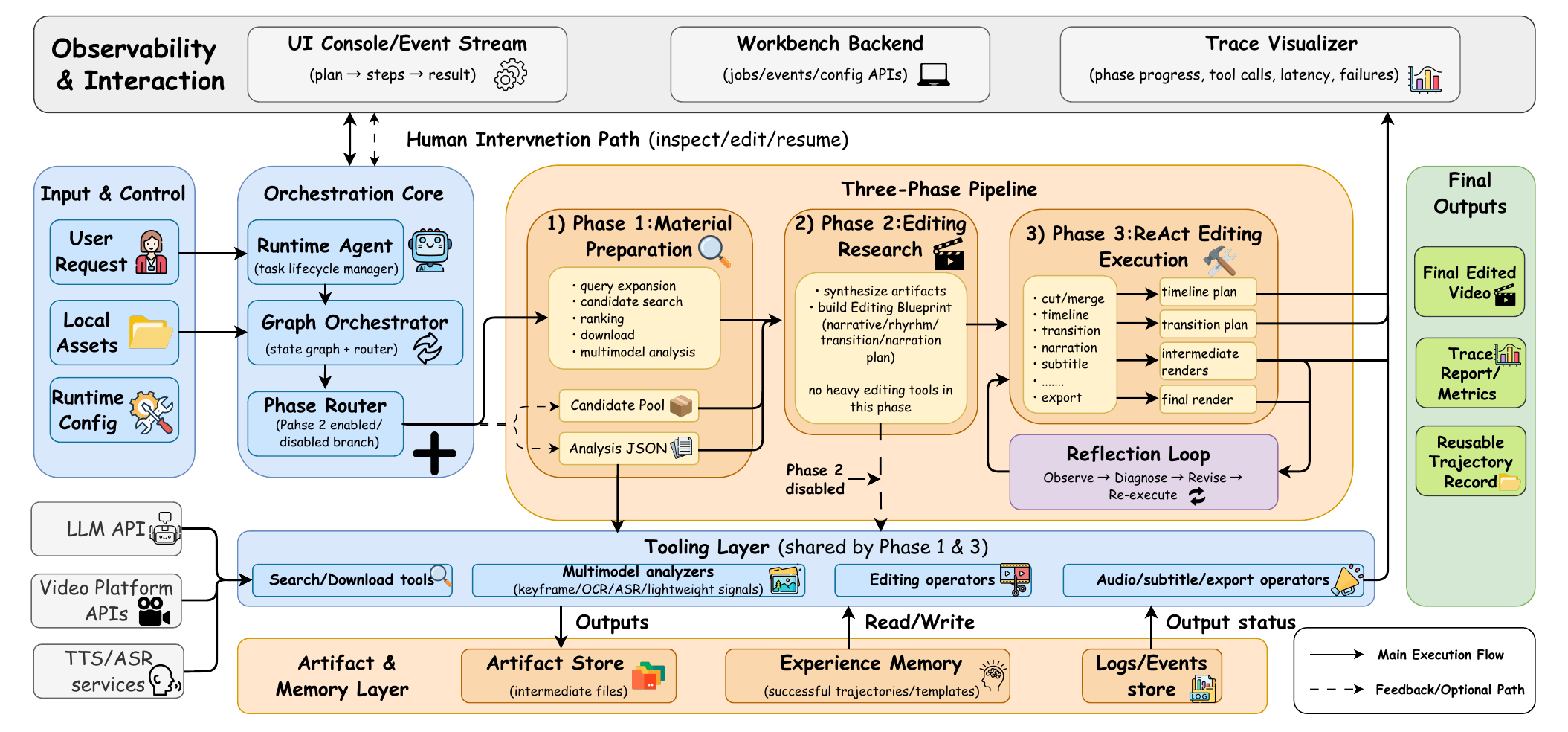
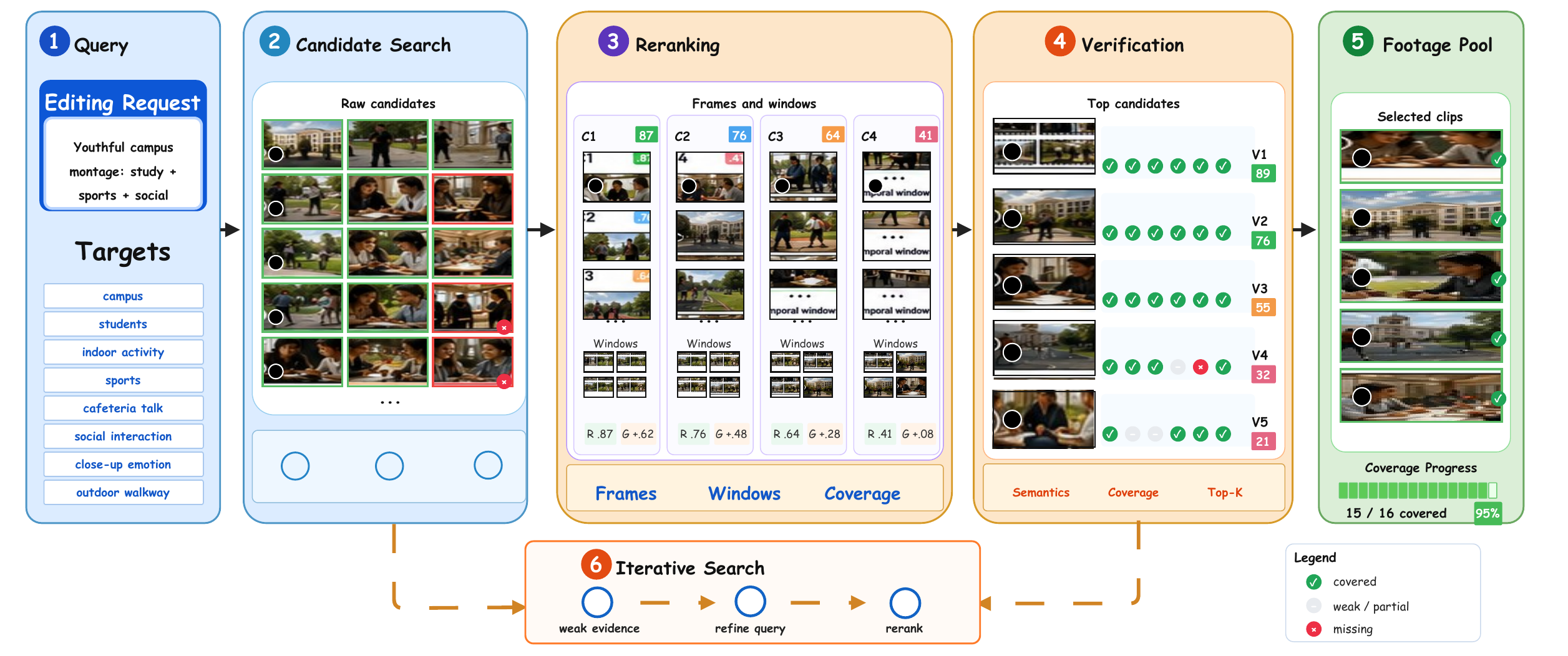
Long-form multimodal editing remains hard because decisions are weakly grounded, intermediate states are hard to audit, and failures are expensive to localize. Crayotter addresses this by mapping a user intent to a finished edited video through three phases: material preparation, deep editing research, and tool-grounded execution.
Its key mechanism is environment-grounded reflection: after each tool action, the agent revises from observable artifacts such as retrieval coverage reports, analysis JSON, timeline plans, previews, and tool logs, rather than from latent traces only.